Imports and Modules¶
Discovery of Dependencies¶
- metatools.imports.discovery.get_toplevel_imports(module)[source]¶
Get the imports at the top-level of the given Python module.
Parameters: module – An actual module; not the name. Returns list: The absolute names of everything imported,
Reloading Code in Production¶
Automatically reloading modules when their source has been updated.
This also allows for some state retention in reloaded modules, for modules to specify dependencies that must be checked for being outdated as well, and to unload those dependencies on reload.
There are two ways that we use to track if something should be reloaded, the last modification time of a file, and the last time we reloaded a module.
The modification time is to determine if a module has actually changed, and if it is newer than a previously seen time, then that module will be reloaded.
Every module reload will store the time at which it reloads (determined at the start of an autoreload cycle). Then, in another autoreload cycle, another module can see when it’s dependencies changes by comparing its reload time with the dependency’s. If a dependency was reloaded, then reload ourselves as well.
This is not perfect, and it is known to cause numerous issues (e.g. circular imports cause some strange problems), however we have found that the problems it brings up are minor in comparison to the speed boost it tends to give us while in active development.
A better algorithm would construct a full module graph (it would not be acyclic), and iteratively expand the region that must be reloaded. Then it would linearize the dependencies and reload everything in a big chain.
The tricky part is since module discovery <discovery> does not reveal the actual intensions of the code, e.g.:
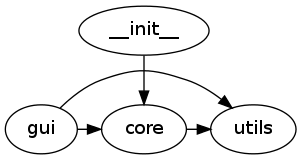
but all the dependancies that it is actually capable of, e.g.:
![digraph discovered_graph {
{rank=same; "core" "gui" "utils"}
"__init__" -> "core"
"core" -> "__init__" [constraint=false]
"core" -> "utils"
"gui" -> "__init__" [constraint=false]
"gui" -> "core"
"gui" -> "utils"
}](_images/graphviz-83144cf48d65f6c77a1f9374c9e075c8d88a775c.png)